The following is a dissertation is based on the Kaggle dataset for the competition "Fake News - Build a system to identify unreliable news articles" . Even though i didn't have the opportunity to participate to the challenge while in progress, i used the same data to analyize throygh text analytics and natural language processing what may be the main classifiers for fake news or reliable news.
Here it follows the paper submitted to Hult International Business School. The code, in R language, is retrievable on my GitHub profile.
Business Insight Report: Fake News
Jacopo Casati
Hult International Business School
The following analysis is based on a Kaggle challenge to discern fake news from real, source-based news (Bisaillon, 2020).
Data exploration and tokenization
The data consists of two cluster of text: Fake and True, with respectively 17,903 examples of fake news and 20,826 examples of real news.
While the fake news is from different subjects (Government, Left, Middle-East, News, Politics, US), the “real” news is focused on only two subjects: Politics and World (IMG 1.1, IMG 1.2). This discrepancy is not reputed risky for the model consistency, but it is probably due to different classifications of different sources of the two clusters.

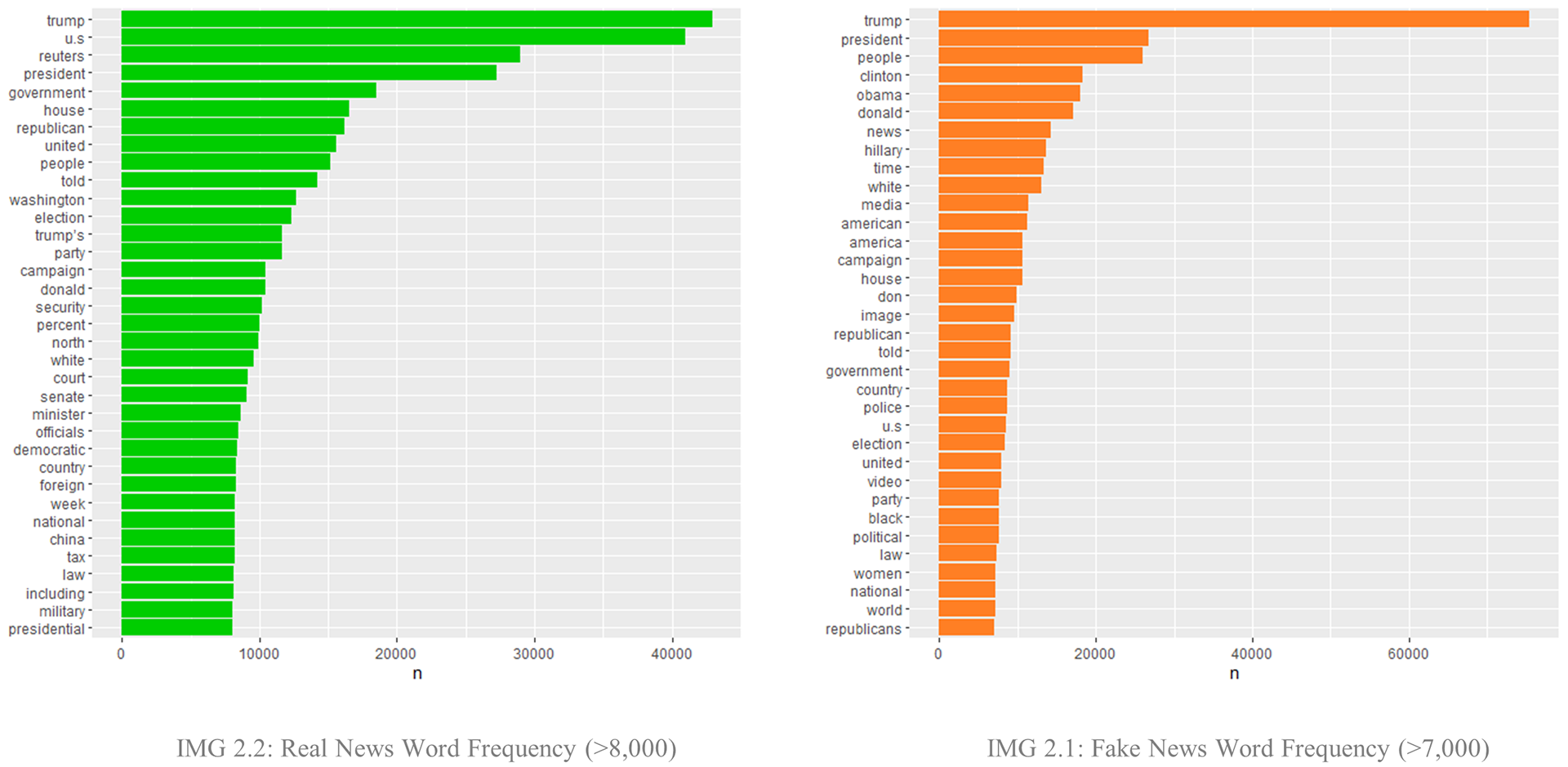
A first look at the most frequent words shows a particular interest in US politics for both groups but with some evident differences in the words. Fake news appears to contain words from a much more popular lexicon (names and simple concepts), while the real news uses more specific terms from the politics field (IMG 2.1, IMG 2.2)
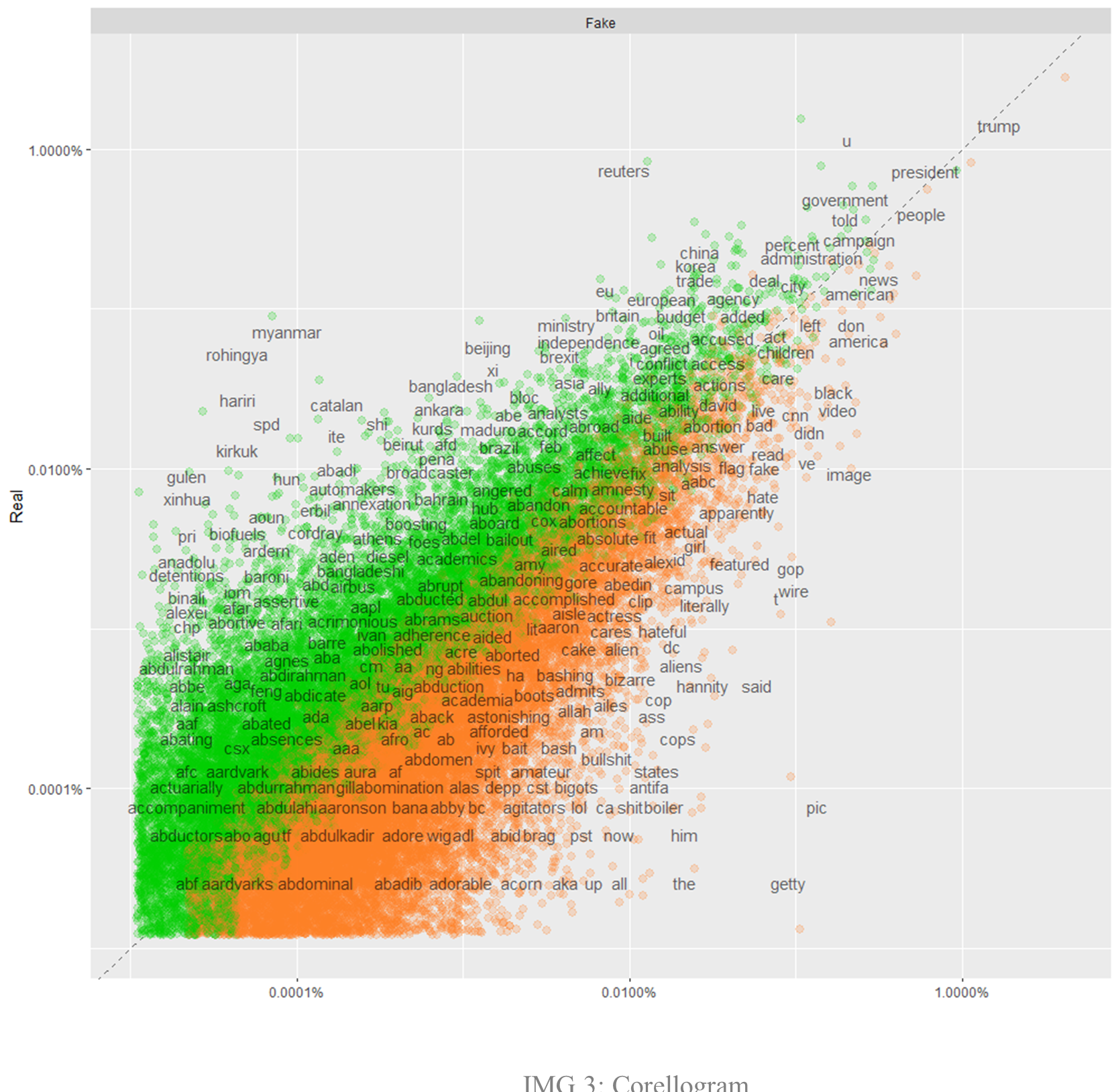
A similar suggestion comes from analyzing the correlogram (IMG 3). Despite a high correlation between the frequencies of the two datasets of 0.88 (still lower than necessary to accept the alternative hypothesis of true correlation not equal to 0), many words are clear indicators of membership of a group or the other.
Indicators of real news are:
- “reuters”
Geographical locations and geographical adjectives
Indicators of fake news are:
- “pic” and synonyms
- Simple words and slang (“cops”, “lol”, “aka”, “ass”, “alien”, …)
Sentiment Analysis
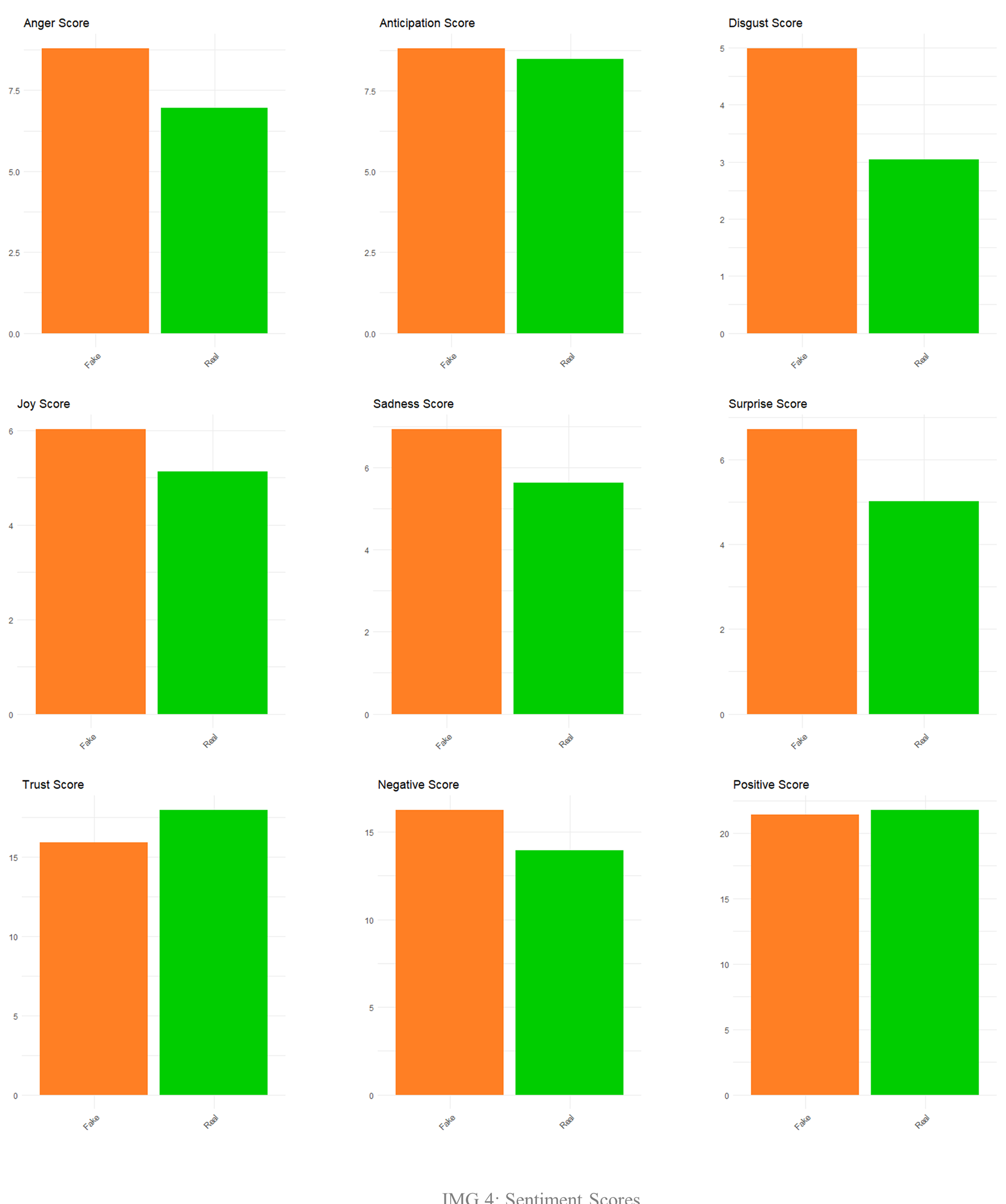
A first analysis through the NRC lexicon allows the attribution of a score for the two clusters on various emotions as joy, anger, sadness, etc.
An emotional score is calculated as the total count of the words belonging to a sentiment category, divided by the amount of news, leading to an “average emotionality per piece of news”.
Not surprisingly, real news has a much higher score in “Trust” and slightly higher in “Positivity”, while fake news dominates in “Fear”, “Negativity”, “Sadness”, “Anger”, “Surprise”, “Disgust”, “Joy”, “Anticipation” (IMG 4).
Further analysis shows that the differences between the two clusters are mostly in intensity rather than in the relative distribution of the emotions. Looking at the distribution of the most common emotional words and their positivity degree, we see only slight differences in the shape of the graphs (IMG 5.1, IMG 5.2, fake in orange and real in green).

TF-IDF Analysis
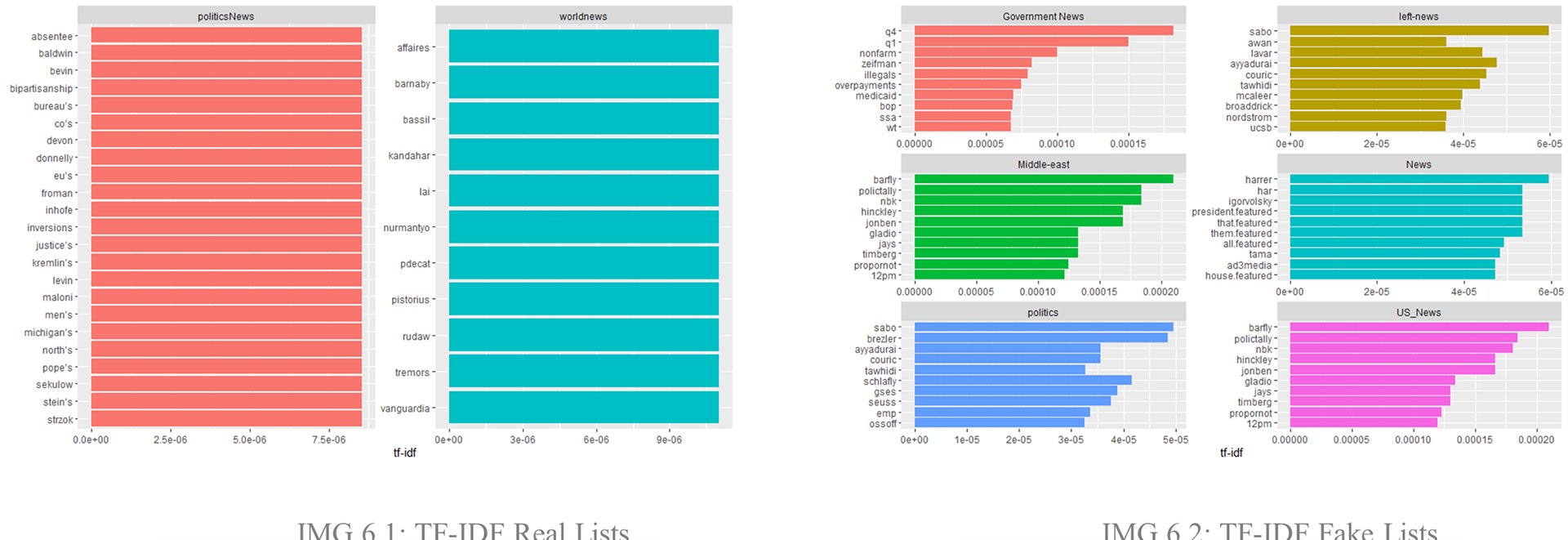
A TF-IDF scoring allows us to look at the main words for every subject for both fake news and real news (IMG 6.1, IMG 6.2). Unfortunately, the sources differ in the way the news subject has been labelled and so a strict comparison it’s impossible. On the other hand, it’s interesting to notice the presence of famous conspiracy theorists and political hot topics in the fake cluster.
Graph Analysis
An analysis of the most recurrent bigrams shows the most trending topics in the news (IMG 7.1, IMG 7.2). The two clusters have many common bigrams, but the Fake group seems much more granular, highlighting what may be the broad creativity of the writers of fake news and the uncorrelation of the news with the reality.
It’s noticeable how “trump” is the main node in the Fake News while the word “reuters”, together with the “us” and “president”, brings together most of the words from Real News.

Insights and Conclusions
The insights found in the above analysis can be summarized in a series of suggestions useful for the reader to discern fake news from real news:
Clear sources are fundamental: the main indicator of fake news is the lack of rigorous sources (ex: Reuters).
Check the background of the sources: pseudoscientists and conspiration theorists are not rigorous sources (ex: Ayyadurai).
Quality of the news = quality of the lexicon: serious journalists rarely use popular words or profanities.
Strong feelings are not a positive clue: strong emotions (both positive and negative) generated by the news are usually correlated to fake news.
Pictures are not (always) proofs: pictures and videos can be misleading (if not even consciously modified) and are often used in fake news to support the story.
Through the results of Natural Language Processing, it would be easy to create a model to predict the membership of a piece of news to a cluster or the other. However, how explained in “Fake News Detection via NLP is Vulnerable to Adversarial Attacks” by Zhixuan Zhou (Zhixuan Zhou, 2019), structuring a model leads the way for accurate fake news engineering based on the factors used by the model itself. Experiments have proven how fake news detection is highly vulnerable when purely based on NLP and suffers from a high rate of false-positive when under adversarial attacks.
In fighting the fake news, it is -and probably will remain to be- fundamental the education of the reader and his/her attention to the details that make fake news an unreliable source of knowledge.
References
Bisaillon, C. (2020, April). kaggle.com/clmentbisaillon/fake-and-real-news-dataset?select=True.csv. Retrieved from kaggle.com: https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset?select=True.csv
Zhixuan Zhou, H. G. (2019). Fake News Detection via NLP is Vulnerable to Adversarial Attacks. Retrieved from arxiv.org/: https://arxiv.org/ftp/arxiv/papers/1901/1901.09657.pdf